
I recently got back from the 2019 American Physical Society Division Nuclear Physics conference where I gave a talk about applying machine learning tools to a signal processing problem in nuclear physics and radiation detection. This post will be some of that talk (here’s a link to the slides).
what problem is this addressing?
In radiation detection systems commonly used in nuclear physics, a charged particle such as a proton or electron hits a cold semiconductor, inducing a charge. That charge is digitized and recorded. When the data acquisition system detects an event, it records the charge in a small amount of time around the event (in my example 14 milliseconds). In a few different cases, multiple particles can hit the detector at the same time, resulting in multiple signals in the same readout. If this isn’t identified, then the data acquisition system misreads the characteristics of the event. This edge behavior has to be caught in a precision experiment! Below is a figure showing what happens when two particles come in closer and closer and have some oscillations in the background.
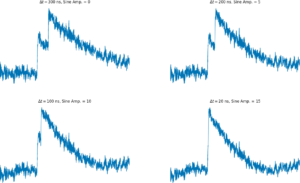
how does this solve the problem?
I approach this problem from two sides. First, I try to develop a supervised learner that can identify this with synthetic data. I implement
- vanilla, 3 layer dense neural networks
- a 3 layer convolutional networks
- an LSTM network — super slow and trains poorly
- a support vector machine
- several ensemble regression methods
- a one dimensional ResNet 50
What I find is that the ResNet 50 does really well for a decent chunk of data (I have as much as I want because I can create synthetic data). Instead of predicting a binary classification, I have the network predict the time delay (and minimize the RMS) so that a threshold can be used to cut the data and the result is more interpretable in terms of where the problems are.
My second approach is to try to find this kind of event in real data from the Calcium 45 experiment. This is very tricky. First, data wrangling is always a hassle, but this event only occurs very rarely in Calcium 45 (but will be about 22% of other experiments’ data rate). I was not expecting to find any pileup, but I was able to find about 10 examples in the data, as well as several other problems with the calcium 45 data (that will be another post!). Here’s a plot of real data – it looks very like the synthetic and has a very small time delay, which gives me hope about using unsupervised methods in the new experiment, Nab.
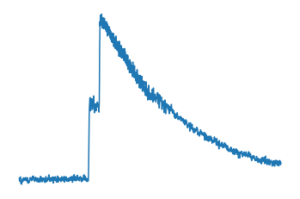
what did I learn?
There are a few takeaways I got from this:
- Labeling data is very time intensive – data exploration is easy when you’re just cruising around, but if you’re looking for a specific effect it’s much harder
- Preprocessing is far more involved than actual machine learning stuff – maybe that’s just the success of modern machine learning libraries, that cleaning up the data is more work than doing ML.
- Sometimes a simple solution is fine – I went with ResNet 50 because I could get more returns if I put the training data to to max, but the simple, 3 layer, convolutional neural net performed pretty well
- Practice makes perfect! – I realized I was bad at public speaking about a year and a half ago and signed up for a bunch of public speaking since then. It was really rewarding to see myself improve.
where’s the code?
Here’s the code: link